
This project is the contribution of Team Jumpstart to the InformatiCup2021 challenge provided by the German Informatics Society (GI). We offer our own AI agent that is able to competitively play the game spe_ed.
The accompanying paper documents our approach. The following video is our submission to the competition final. It gives an overview of our development process and the different methods used in our solution (German, english subtitles).
Methods
Path Length Heuristic
The path length heuristic performs a random walk up to a certain number of steps (e.g. 5). The action leading to the longest path is selected, as longer paths imply a strong possibility of surviving longer. Performing only one walk in each direction might lead to a strong variation. Therefore, we perform multiple walks for each available action and select the longest path available. If we reach the maximal number of allowed steps, we can opt out for the specified initial direction, as our value already reached the maximum.
Region Heuristik
The region heuristic computes a score for each region. A high score indicates a large region with few opponents, whereas a low score represents a small, unattractive region. To obtain region score, it divides the number of available cells by the number of opponents plus one. Big regions allow us to perform more actions and thus survive for a longer period of time. However, opponents are a non-negligable factor to consider as well, since having to share a region with another player makes the region less desirable. Furthermore, encountering opponents might result in unnecessary fights, that will additionally divide the region.
Region Heuristik with Jumps
The value of the region heuristic does not change a lot from one step to another. However, simulating multiple future steps might lead to a drastic change in value, since jumps become more likely. This can motivate the agent to speed up and perform a jump into a different region with a better score. Ultimately, one could even assign the region value to each single cell and smooth it out as a gradient to reach the position with the biggest available space around it.
Region Heuristik Monte-Carlo
Simulating only one random path often leads to unsatisfactory results. To mitigate the risk of performing one wrong action and thus missing the perfect move, we perform a Monte-Carlo simulation. More precisely, we simulate multiple paths for each available action and select the best possible result. In this way, we are able to neglect the negative impact of the stochastic approach of randomized walks and reduce the variance of our obtained results.
Morphological Operations
Morphological operations allow us to virtually manipulate the board state to account for different scenarios, such as jumps or opponents closing small chocking points. An opening operation opens all one and two cell wide walls, to acknowledge the possibility of simple jumps, that can easily cross neighbouring regions. In this way, we are able to connect divided regions and approximate the upper limit of safely reachable cells. On the contrary, the closing operation closes all one and two cell wide openings. Thus, it is a extremly conservative approximation of the available cell space, accounting for enemies closing small gaps and connections between two connected regions. It allows us to avoid entering corridors, which might be a trap for our agent and result in a not immidiate, but certain death.
Occupancy Map
The occupancy map computes the probability for each cell, that it will be occupied in the near future. To obtain the value, we simulate each possible move of each player and aggregate the probabilities of valid moves on the map. That means, we encode the risk attributed to entering a cell in the occupancy map. As a result, our agent is able to dodge opponents more easily. Consequently, we are able to conceptionally abstract the multi-player game into a single-player game with additional uncertainity.
Policy Clustering
State Abstraction
For the considered Reinforcemnet Learning approaches, a game state representaion with constant size is desirable. Therefore we propose this state abstraction:
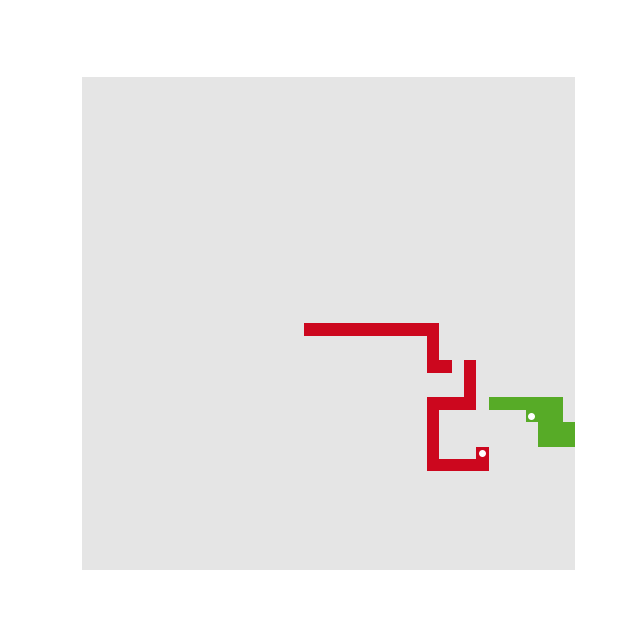

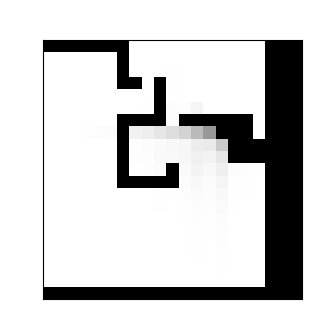


This state representation only consists of a square image and thus is well suited as input for a convolutional neural network. With a radius of 10, the reduced state space has a dimension of ℝ21×21.
State Clustering

As similar states are likely to result in similar actions. Experimental clustering with K-means lead to state clusters as shown above. However, K-means is not necessarily well suited for this task as not all cells have equal impact on the policy.
Policy Clustering

Different policies differ in that they choose different actions for the same state. This leads to the idea for our policy abstraction. For each state cluster, we compute the action distribution of the policy. This leads to a compact, fixed size approximation of the policy.
These approximations again can be clustered, resulting in a policy clustering. Then, while playing we can compute the action distributions for each opponent and match them against the known policy clusters. From the corresponding cluster, we can infer action probabilities and thus can predict future actions of opponents.
However, the algorithm for policy clustering is critical. The employed expectation–maximization algorithm suffered from overfitting/being stuck in local optima and converged immediately. Thus, the policy clustering road is still to be explored.
Analysis
Win Rate
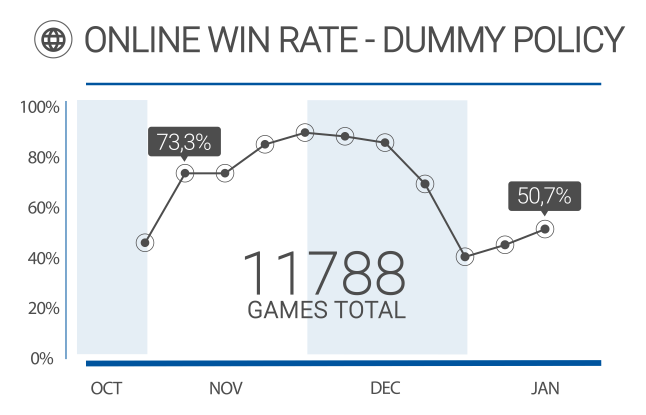
This diagram visualizes the win rate of our dummy policy (Adam) during the tournament. Our agent was able to achive a win rate of over 50%, despite using a simple strategy. It performs a limited depth-first search for the longest path and performs its first action, after a fixed amount of searched paths. This straigthforward strategy was able to consistently win against server bots, which do not show complex behaviors, but was not supposed to beat high-level strategies. This way, we were able to coarsly filter interessting games, by finding those policies that could consistently beat ours. To our surprise, the online competition was not very fierce, as it won most of its played games. Thus, we could deduce, that our opponents neglected the online server in favor of offline play or intentionally held back their sophisticated strategies.
Opponents Scatter Plot
An in depth analysis of our online opponents showed, that initially most of our encountered enemies were server bots. Later on, logging bots of other teams appeared. Those also played permanently on the server, but did not show any reasonable strategies. We had to assume they were only collecting data, similar to us. Other teams with more advanced policies were rare. This situation changed two weeks before the end of the tournament. We encountered more interessting enemies with stronger strategies.
Tournament Statistics
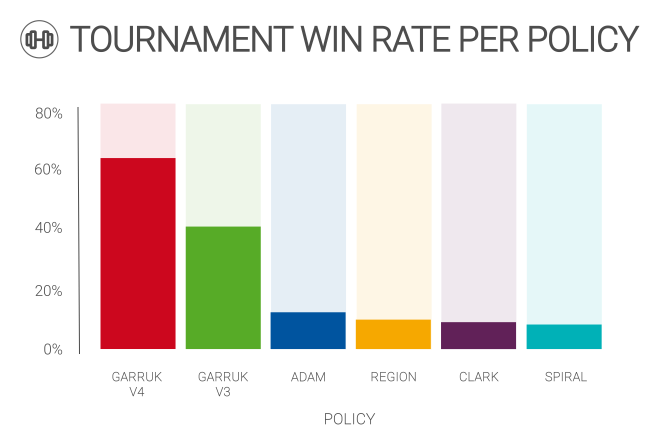
Our local tournament environment allows us to simulate hundreds of games in a short period of time. With this tool we were able to optimize our final combination of heuristics by playing against other iterations. With variations in the number of players, the board size and the number of players, we can create the perfect enviroment to filter out the best policy among the competitors. Each matchup is evaluated individually against each other policy, as well as aggregated as an overall win rate. Thus, we can fine tune our policies in an evolutionary fashion.
The policy shown above are:
GarrukV3 was the policy submitted to the InformatiCup2021 challenge.